2008/08/25 - [NDS/NDS_Palib] - Palib - 문자인식 Shape Recognition
Palib의 문자인식(필기인식)은 그럼 어떤 알고리즘으로 하는걸까.
PA_CheckLetter 함수부터 하나씩 따라가보자.
그리고 Released시에 저장된 값들로 모양을 인식한다. PA_AnalyzeShape 함수 이며 제일 중요한 함수이다.
7행 저장된 모든 위치값에서 16개(17개?)의 표본을 뽑아낸다.
(기본적으로 16개의 표본으로 잡고있다. 이 값을 늘린다면 더욱 정밀한 필기인식이 가능할수도 있지만 그 반대가 될수도 있다)
23행 뽑아낸 16개의 위치로 순서대로 연결된 위치끼리의 15개의 각도를 구한다.
25행 이 각도를 문자로 치환한다.
문자는 0x30 - 0x4F의 32가지 문자가 사용되며 0123456789:;<=>?@ABCDEFGHIJKLMNO 이다.
NDS는 360도 원이아닌 아닌 512도 원을 쓰기때문에 문자마다 16도의 범위를 가지고있다.
L은 각도를 가지고있긴하지만 만약 각도가 없는경우에 L로 치환 된다. ( . ) 처럼 이동이 없는 경우에 속한다.(이유는 모르겠다;)
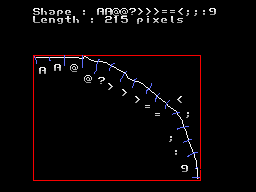 정확하진 않지만 대략 비교 해보면 위 이미지처럼 설명 할수있다. 위의 원 문자표와 비교해보면 비슷하게 나오는것을 볼수있다.
정확하진 않지만 대략 비교 해보면 위 이미지처럼 설명 할수있다. 위의 원 문자표와 비교해보면 비슷하게 나오는것을 볼수있다.
각도를 뽑아냈으니 이제 어떤 문자인지 인식해야한다.
34행과 51행의 차이는 기본 제공하는 문자인식 자료를 사용할지 안할지 체크하는 것이다.
PA_UsePAGraffiti 함수로 설정한다.
기존 자료를 사용할경우로 보면...
35행 자료의 모든 문자와 비교를 한다.
38-43행 이 부분이 두자료를 비교하는 부분이다.
39. tempvalue = (PA_RecoShape[i]-PA_Graffiti[j].code[i])&31;
두 자료의 차를 저장하고있는데 이 값이 같다면 같은 각을 가지고 있는 것일테고 값이 다른 자료보다 크다면 각이 전혀 다르다는걸 의미하는 것이다.
42행 이 값들을 계속 합하여 한 문자의 총 계산값이 나오고
45-48행 문자 마다 비교해서 계산값이 가장 작은 문자를 저장한다.
72행 모든 자료의 비교가 끝나고 저장된 문자를 리턴한다.
아직 자료로 구축해서 테스트 해보진 않았지만 눈에 띄는 문제점이 하나 보인다.
39행의 두 자료의 차로 계산하는 방법인데 위치가 15개의 각도중에서 같은 위치끼리만 비교하고 있다.
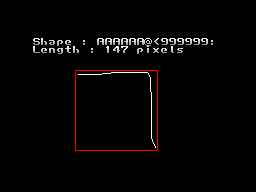
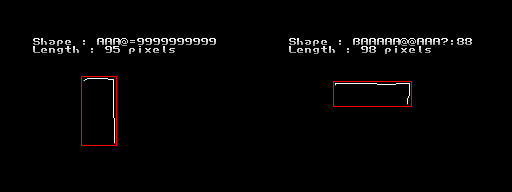 셋다 "ㄱ" 이긴하지만 FM 이라면 "AAAAAAA=9999999" 정도가 맞다.
셋다 "ㄱ" 이긴하지만 FM 이라면 "AAAAAAA=9999999" 정도가 맞다.
1번은 당연히 맞게 나올것이지만 같은 위치의 값들만 비교하기때문에 2, 3번은 diff 값이 1번보다는 많이 올라갈것이다.
원하지 않는 문자보다 diff값이 더 커질 가능성도 있다. 그러면 ㄱ으로 인식하지 않게 된다.
이 문제의 해결방법이라면 각도가 크게 변하는 구간을 따로 계산하는것이다. 즉 꺽이는 부분 이전과 이후로 계산한다는 말인데 이 방법이라면 위 세 경우 모두 비슷한 diff값을 가질것이다.
말은 쉽다. 원래 방법만으로도 충분할수 있으니 이 방법은 우선 생각만 해두기로 하자.
인식률이 높은 알고리즘도 있겠지만 보통의 필기인식 프로그램의 경우 정자(최대한 바른)를 요구하는것은 위와 같은 이유로 생기는 오류를 최대한 방지 하려는 것이다. 하지만 그 사용자에게 요구하기보다 사용자의 상황에 맞는 알고리즘을 구현하는것이 더 나은 소스일듯하다.
대충 분석을 하고 이해를 했으니 이제 실제 DB를 구축하여 테스트 해보아야 한다.
한참 머리 싸매야 할듯...
 invalid-file
invalid-filePalib에 포함된 Shape Recognition 내용 파일
Palib의 문자인식(필기인식)은 그럼 어떤 알고리즘으로 하는걸까.
PA_CheckLetter 함수부터 하나씩 따라가보자.
char PA_CheckLetter(void){
if(Stylus.Newpress){
PA_Reco.nvalues = 0; // Start over again
PA_Reco.oldn = 0;
PA_Reco.veryold = 0;
PA_RecoInfo.startX = PA_StylusPos[PA_Reco.nvalues].x = Stylus.X; // start values
PA_RecoInfo.startY = PA_StylusPos[PA_Reco.nvalues].y = Stylus.Y;
PA_RecoInfo.minX = PA_RecoInfo.maxX = PA_RecoInfo.startX;
PA_RecoInfo.minY = PA_RecoInfo.maxY = PA_RecoInfo.startY;
PA_Reco.nvalues++;
}
else if(Stylus.Held) {
PA_StylusLine(PA_StylusPos[PA_Reco.nvalues-1].x, PA_StylusPos[PA_Reco.nvalues-1].y, Stylus.X, Stylus.Y);
}
if(Stylus.Released){ // Start analyzing...
PA_Reco.nvalues = PA_Reco.veryold;
return PA_AnalyzeShape();
}
PA_Reco.veryold = PA_Reco.oldn;
PA_Reco.oldn = PA_Reco.nvalues;
return 0;
}
간단히 Newpress/Held시와 Released시로 나눌수 있는데 Newpress때엔 값을 초기화하며 첫위치를 잡아준다. Held시에 스타일러스가 이동하는 위치마다 값을 저장하는데 단순히 터치인식 위치가 아니라 PA_StylusLine(PA_DrawLine과 소스가 거의 같다)함수로 터치 위치끼리 이어진 좌표까지 모두 저장한다.그리고 Released시에 저장된 값들로 모양을 인식한다. PA_AnalyzeShape 함수 이며 제일 중요한 함수이다.
7행 저장된 모든 위치값에서 16개(17개?)의 표본을 뽑아낸다.
(기본적으로 16개의 표본으로 잡고있다. 이 값을 늘린다면 더욱 정밀한 필기인식이 가능할수도 있지만 그 반대가 될수도 있다)
23행 뽑아낸 16개의 위치로 순서대로 연결된 위치끼리의 15개의 각도를 구한다.
25행 이 각도를 문자로 치환한다.
문자는 0x30 - 0x4F의 32가지 문자가 사용되며 0123456789:;<=>?@ABCDEFGHIJKLMNO 이다.
NDS는 360도 원이아닌 아닌 512도 원을 쓰기때문에 문자마다 16도의 범위를 가지고있다.
L은 각도를 가지고있긴하지만 만약 각도가 없는경우에 L로 치환 된다. ( . ) 처럼 이동이 없는 경우에 속한다.(이유는 모르겠다;)
선부터 다음선 사이의 간격이 아니라 선 양쪽으로 16도가 그 문자의 범위다.
각도를 뽑아냈으니 이제 어떤 문자인지 인식해야한다.
34행과 51행의 차이는 기본 제공하는 문자인식 자료를 사용할지 안할지 체크하는 것이다.
PA_UsePAGraffiti 함수로 설정한다.
기존 자료를 사용할경우로 보면...
35행 자료의 모든 문자와 비교를 한다.
38-43행 이 부분이 두자료를 비교하는 부분이다.
39. tempvalue = (PA_RecoShape[i]-PA_Graffiti[j].code[i])&31;
두 자료의 차를 저장하고있는데 이 값이 같다면 같은 각을 가지고 있는 것일테고 값이 다른 자료보다 크다면 각이 전혀 다르다는걸 의미하는 것이다.
42행 이 값들을 계속 합하여 한 문자의 총 계산값이 나오고
45-48행 문자 마다 비교해서 계산값이 가장 작은 문자를 저장한다.
72행 모든 자료의 비교가 끝나고 저장된 문자를 리턴한다.
아직 자료로 구축해서 테스트 해보진 않았지만 눈에 띄는 문제점이 하나 보인다.
39행의 두 자료의 차로 계산하는 방법인데 위치가 15개의 각도중에서 같은 위치끼리만 비교하고 있다.
1번은 당연히 맞게 나올것이지만 같은 위치의 값들만 비교하기때문에 2, 3번은 diff 값이 1번보다는 많이 올라갈것이다.
원하지 않는 문자보다 diff값이 더 커질 가능성도 있다. 그러면 ㄱ으로 인식하지 않게 된다.
이 문제의 해결방법이라면 각도가 크게 변하는 구간을 따로 계산하는것이다. 즉 꺽이는 부분 이전과 이후로 계산한다는 말인데 이 방법이라면 위 세 경우 모두 비슷한 diff값을 가질것이다.
말은 쉽다. 원래 방법만으로도 충분할수 있으니 이 방법은 우선 생각만 해두기로 하자.
인식률이 높은 알고리즘도 있겠지만 보통의 필기인식 프로그램의 경우 정자(최대한 바른)를 요구하는것은 위와 같은 이유로 생기는 오류를 최대한 방지 하려는 것이다. 하지만 그 사용자에게 요구하기보다 사용자의 상황에 맞는 알고리즘을 구현하는것이 더 나은 소스일듯하다.
대충 분석을 하고 이해를 했으니 이제 실제 DB를 구축하여 테스트 해보아야 한다.
한참 머리 싸매야 할듯...
'NDS' 카테고리의 다른 글
| Palib - 문자인식 Shape Recognition (0) | 2008.08.25 |
|---|---|
| Palib - PA_16bitDrawCircle 함수 (6) | 2008.08.25 |
| PA_Draw 는 어떻게 그려질까? 2 (0) | 2008.08.25 |
| PA_Draw 는 어떻게 그려질까? (2) | 2008.08.22 |
| NDS SuChupDS 0.2.1 BMP 저장 이미지 (0) | 2008.08.22 |


